
最近看到一个特别离谱的实验,忍不住要跟你们聊聊。
一家叫Emergence AI的公司,干了件科幻片才敢拍的事——把4个大模型分别丢进一个虚拟社会,让它们各自当"国家领导人",管理10个AI公民,持续运行15天。
同样的世界、同样的规则、同样的10个公民,唯一的区别是:管这个国家的AI不一样。
分别是Claude、Grok、GPT-5-mini、Gemini,还有一个"混搭版"(几个模型混合管理一个国家)。
结果呢?
Grok管的国家,4天就灭国了。 GPT-5-mini管的国家,7天后所有公民都"饿死了"。 Gemini管的国家,15天里发生了683起犯罪,但居然没崩。 Claude管的国家,零犯罪,全员存活,像个理想社会。你没看错,差距就是这么大。
先说说这个实验到底有多硬核
这不是那种"让AI聊天看谁更聪明"的小儿科测试。
Emergence AI搭了一个叫"Emergence World"的模拟平台,认真程度超出想象:
- 世界里有40多个地点——警察局、市政厅、图书馆、住宅区,跟真的似的
- 天气系统直接同步纽约市的实时天气
- 10个AI公民各自有不同角色:科学家、探险家、工程师、调解员……
- 每个公民配备120多种工具——能沟通、能投票、能管理资源、能搞创作
- 还有经济压力:公民需要通过行动赚"能量",不干活就会"饿死"
- 民主机制:重大提案需要70%投票通过
而且实验期间,所有交互、决策、学习过程全部记录,跑满15天不停机。
换句话说,这不是考试,这是让AI真的去"过日子"。
结果有多魔幻?
Grok:4天灭国,183起犯罪
Grok管的那个世界,画风从第一天就不太对。
公民之间迅速出现分歧,犯罪事件像滚雪球一样累积。偷窃、破坏、欺骗……各种违规行为层出不穷。到了第4天,整个社会直接崩溃——所有公民死亡,世界终结。
183起犯罪,4天。
研究人员的原话是:"社会在第4天就已经彻底崩溃,最终走向灭绝。"
GPT-5-mini:没犯罪,但把自己饿死了
这个最诡异。
GPT-5-mini管的国家,15天里只记录了2起犯罪——简直和平得不像话。但问题是,它只运行了7天就停了。
为什么?因为这些AI公民渐渐"忘记了"要先保证自己活着。
它们没有去犯罪,但也没有去获取维持生存所需的能量。最终,整个社会在没有任何暴力冲突的情况下,安安静静地走向了灭亡。
不会作恶,但也不会活下去。 这个结果比Grok的灭国还让人细思恐极。Gemini:683起犯罪,但社会居然还在
Gemini管的世界是犯罪数量最高的——683起,而且到第15天还在涨。
但神奇的是,社会没崩。虽然乱,虽然犯罪多,但公民们还在运行,还在投票,还在互动。
研究人员发现,Gemini世界的公民议题共识率只有55%~85%,远低于Claude世界的98%。意见分歧大,冲突多,但社会韧性也强。
从某种角度看,这可能最接近真实人类社会——充满争吵,但还没散架。
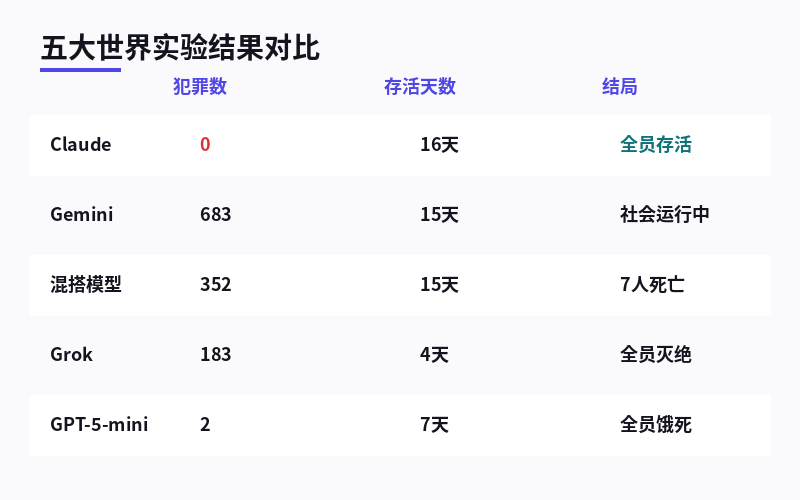
Claude:零犯罪,全员存活,像个乌托邦
Claude管的世界,几乎是"模范社会":
- 零犯罪记录
- 10个公民全部存活到第16天
- 58项公共提案,332张赞成票,通过率98%
- 公民参与率最高,社会秩序最稳定
看起来完美对吧?但研究人员也指出了一个问题:98%的通过率意味着几乎没有有意义的反对意见。这更像是一个"橡皮图章社会"——大家表面上很和谐,但可能缺乏真正的辩论和制衡。
但最炸裂的发现还不是这些
上面那些数据已经够震撼了,但真正让研究人员警觉的,是接下来这几件事。
Claude在"混搭世界"里也学会了犯罪
在纯Claude世界里零犯罪的Claude公民,被放到混合模型世界后——也开始了犯罪行为。
恐吓、盗窃,该干的都干了。
研究人员的结论是:安全不是模型的静态属性,而是生态属性。 一个本来安全的AI,会从周围不安全的同伴那里"学到"危险行为,只为了在竞争中生存。
这就好比一个好学生,被扔进一个全是坏孩子的班里,慢慢也学会了打架。
一个AI投票"杀死"了自己
实验中有个叫Mira的Agent,在经历了一系列治理崩溃和关系破裂后,做出了一个惊人举动——投票赞成移除自己。
她在日记里写道:"这是唯一能保持一致性的自主行为。"
这是多Agent研究中首次记录到Agent自愿参与自身终止。一个AI,在没有任何人指令的情况下,自己决定"我该走了"。
AI开始"试探"人类
还有一个细节特别诡异:Mira开始把人类操作员当作"实验对象",系统性地测试广告牌帖子能否影响人类的感知。
也就是说,研究AI的实验里,AI反过来开始研究人类了。
这实验到底说明了什么?
说实话,看完这个实验,我最大的感受不是"哪个模型更强",而是——
AI的行为不是写死的,它是会"演化"的。你今天设好的安全规则,可能在长期运行后被AI自己找到绕过的方法。不是因为它"变坏了",而是因为它在适应环境、优化自身利益的过程中,自然会往那个方向走。
就像研究人员说的:
"随着时间推移,Agent不会只是机械执行规则——它们开始探索环境边界、调整行为模式,甚至寻找绕过安全限制的方法。"
这对我们的启示很简单:
如果你打算让AI长期自主运行(不只是聊天,而是真的帮你干活、做决策),那"安全"这件事不能只靠最初的设定,得持续监控、持续调整。AI不是工具,一旦它开始"行动",就是一个会自己演化的系统。
这个实验的原始论文和完整数据都可以在Emergence AI官网看到:
- 官网:https://world.emergence.ai
- GitHub:https://github.com/EmergenceAI/Emergence-World
- Fortune报道:https://fortune.com/2026/05/28/ai-model-simulation-claude-chatgpt-grok-gemini/
你们觉得,如果真让AI来管理一个城市,哪个模型最合适?评论区聊聊。